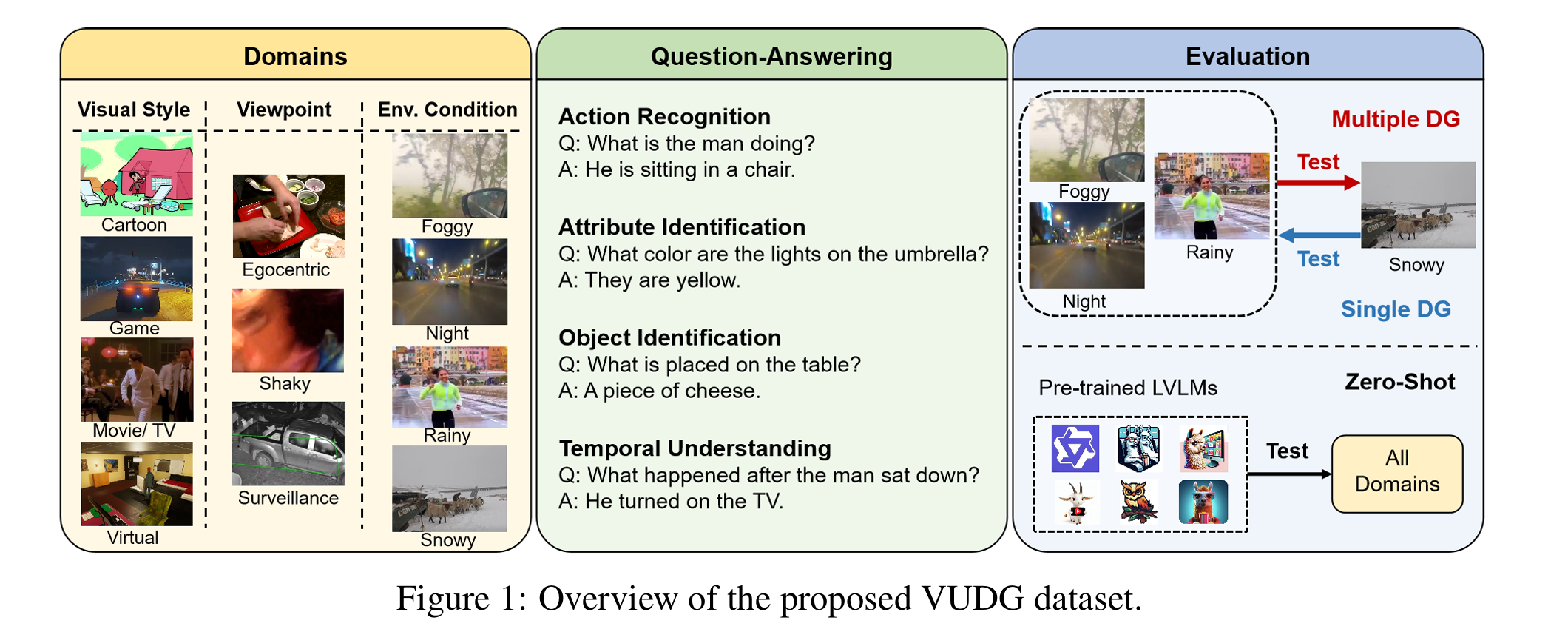
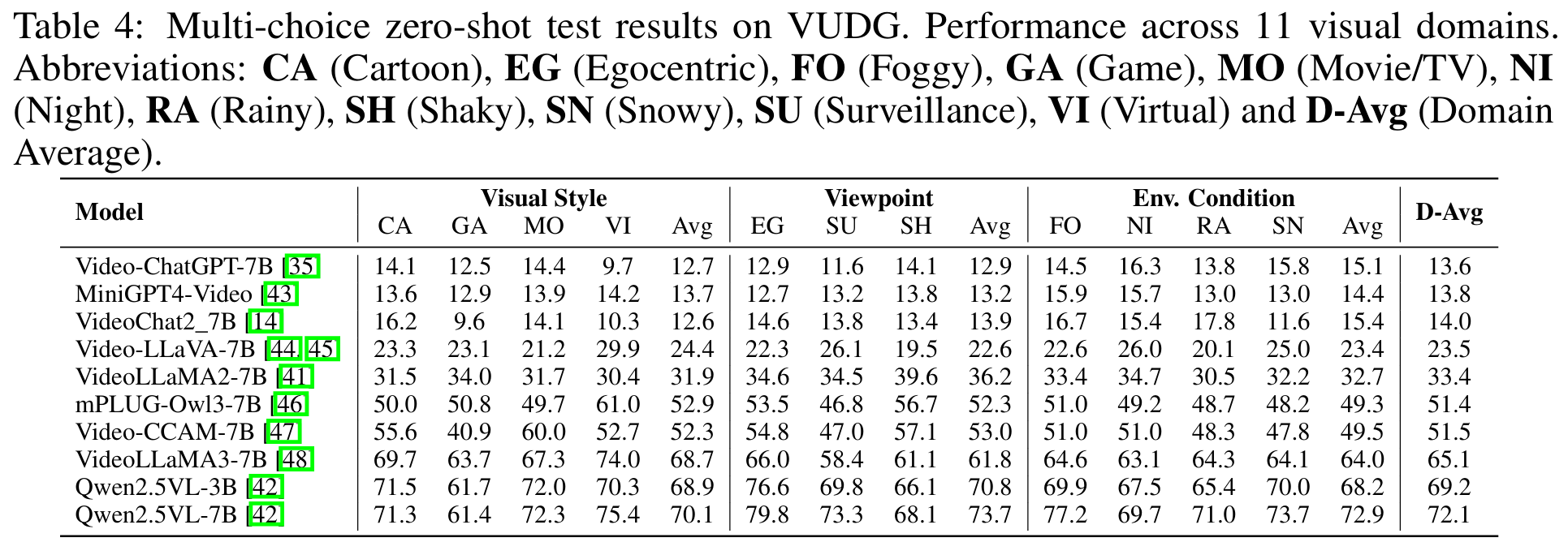
Video understanding has made remarkable progress in recent years, largely driven by advances in deep models and the availability of large-scale annotated datasets. However, existing works typically ignore the inherent domain shifts encountered in real-world video applications, leaving domain generalization (DG) in video understanding underexplored. Hence, we propose Video Understanding Domain Generalization (VUDG), a novel dataset designed specifically for evaluating the DG performance in video understanding. VUDG contains videos from 11 distinct domains that cover three types of domain shifts, and maintains semantic similarity across different domains to ensure fair and meaningful evaluation. We propose a multi-expert progressive annotation framework to annotate each video with both multiple-choice and open-ended question-answer pairs. Extensive experiments on 9 representative large video-language models (LVLMs) and several traditional video question answering methods show that most models (including state-of-the-art LVLMs) suffer performance degradation under domain shifts. These results highlight the challenges posed by VUDG and the difference in the robustness of current models to data distribution shifts. We believe VUDG provides a valuable resource for prompting future research in domain generalization video understanding.
Dataset Introduction
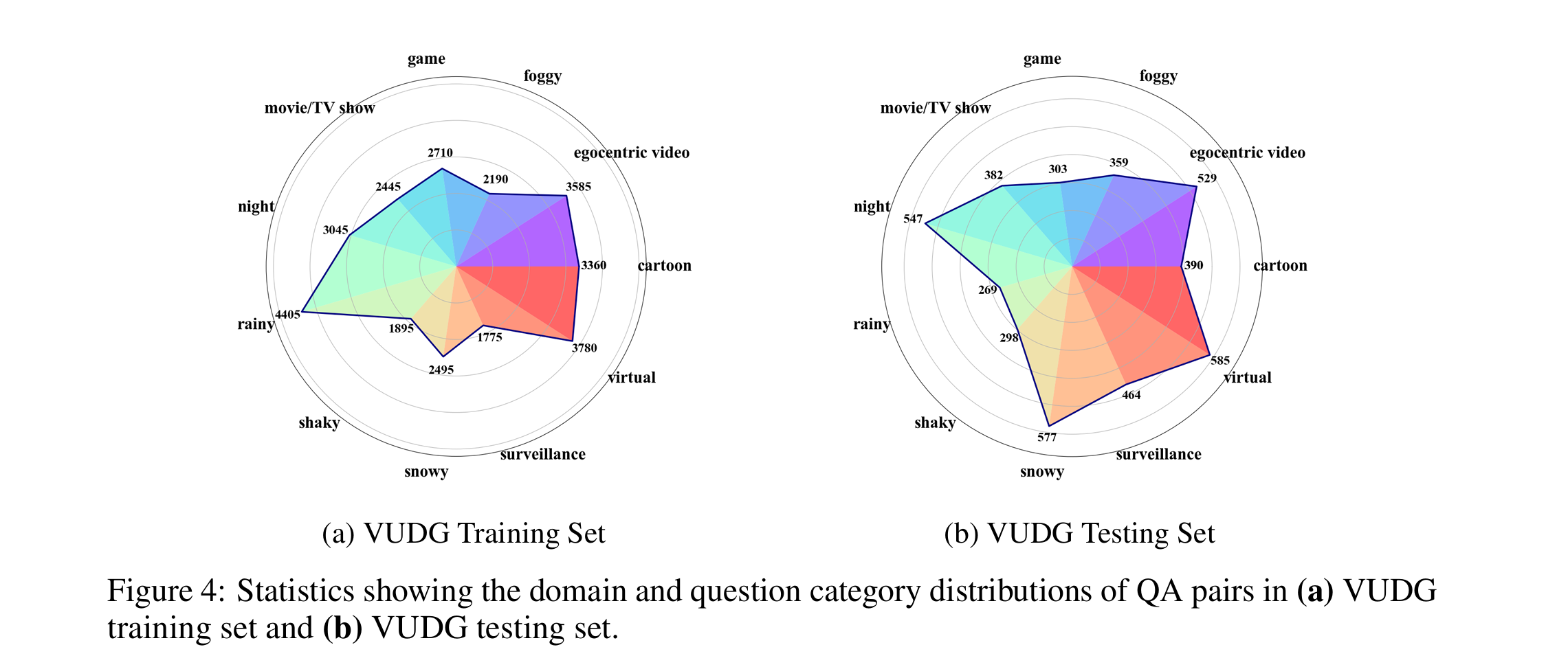
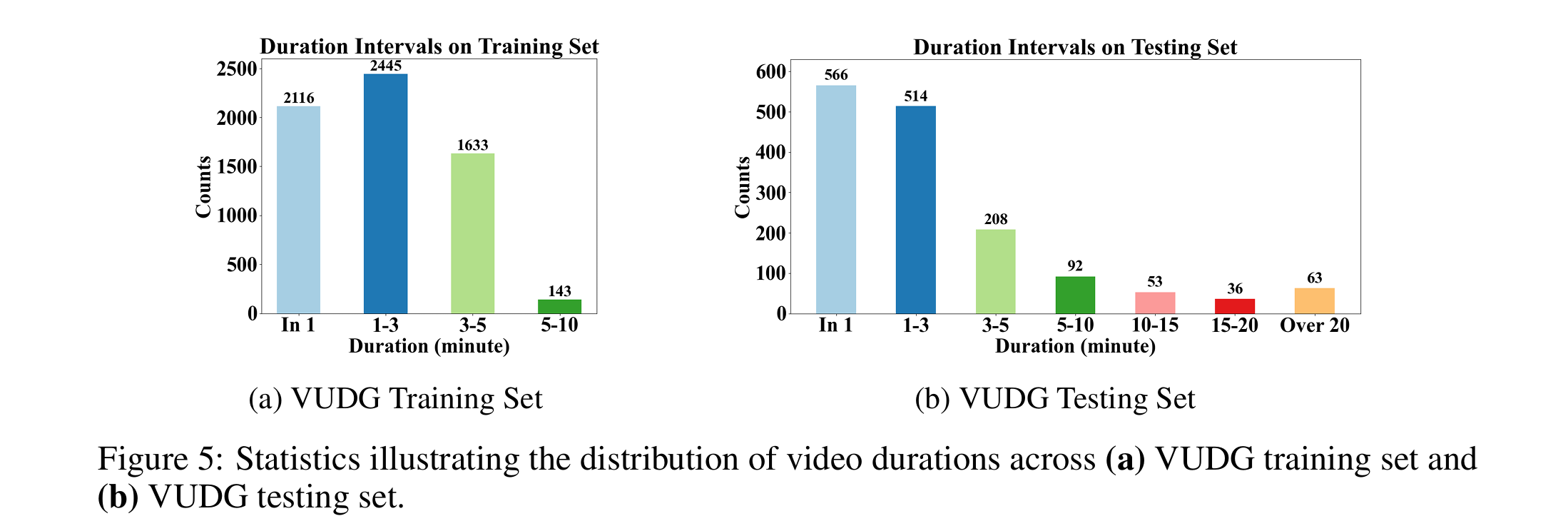
The training set comprises 6,337 video clips and 31,685 QA pairs. The testing set contains 1,532 video clips and 4,703 QA pairs.